In this article

Best practices
The risks and pitfalls of poor tracking documentation and oversight: Part 1
Here at Avo, a big part of our passion for building the best solution for data quality in product analytics is based on our own lived experience. Our Head of Data Sang Park joined Avo as a means of giving back to the analytics community and hoping to prevent the exact headaches and frustrations that he has dealt with over his years working in product analytics. Read about how he encountered challenges with data discoverability and documentation as soon as he started his career in analytics, and how Avo could have helped
I’m no stranger to broken, ambiguous, and/or undocumented data.
Prior to joining Avo, I spent a decade wrangling and cleaning data in analytics and data science roles across a range of companies with varying sizes and tech stacks. While I observed significant variation in the overall data quality at different workplaces based on their respective maturity and/or data resourcing, it didn’t change the fact that I would always take a deep breath before diving into a product area that hadn’t been touched in a while. And yes, this was true even at Meta fka Facebook, which I would consider to be one of the most analytics-friendly workplaces I’ve ever encountered.
This isn’t unique to me. Many of us have heard that 60% of data professional time is spent on data cleaning and organizing, as per the frequently-cited Crowdflower report from 2016. Across different workplaces and teams, analysts and data scientists are spending significant time and energy on unenjoyable work that could be preempted by robust data design and documentation.
Why does this happen in a world where global interest in product analytics is spiking to all-time highs and data science is considered the sexiest job in the world? Well, I imagine you’re here to read about why (or to have your own frustrations validated). Let’s get into some of the most common pitfalls of poor and/or incomplete data design and documentation - and how Avo can help you avoid them.
Pitfall: “Help, I have no idea what any of these events or fields mean and I don’t know who or what can help!”
I encountered this problem in my first week after joining the Facebook Growth team. I then encountered it repeatedly on every team and workplace since, but let’s focus on the first time so that this doesn’t end up becoming a full-blown book about my data misadventures.
One of my first tasks was to set up the data pipeline and create the first comprehensive dashboard around the People You May Know (PYMK) feature. While there wasn’t much existing documentation around the dataset, the Growth Marketing Manager on the team could point me to the relevant table and the high-level context of what it covered. When it came to the details of what different fields and values meant, though, he was only confident in the most common values - leaving the numerous secondary events as unknowns. He was also the authority on the team when it came to this dataset, as the people who had originally instrumented the data weren’t available to me for various reasons. I had nowhere else to turn for more information.
What followed was two weeks of onboarding into both the PYMK product and all of Facebook’s (admittedly world-class) data debugging and data monitoring tools. Read: I learned how to utilize all of the debuggers and real-time data tracking tools available to me in my quest to trigger and document every possible impression and click on PYMK. I worked with our ranking engineers to dig into the codebase and figure out the events and values that I wasn’t able to trigger for myself. Only then was I able to start modeling and dashboarding the data - which actually took less time than the data re-discovery I had to do prior.
Unfortunately, the struggle didn’t end with me. This problem then repeated itself over time as other data scientists and engineers attempted to use this dataset after I moved on to other product areas. I made my best effort to counter these issues by appending table and column descriptions both at the schema view and dashboard levels, as well as writing a Wiki page that captured the extent of my knowledge. These data sources ended up being only somewhat useful because people didn’t know where to look for information. While I saved myself the time necessary to fully onboard others onto PYMK data, I still had to send people the documentation each time someone had a question…all the way until my last month at Facebook, nearly five years after I joined and three years after PYMK was fully outside of my direct responsibilities.
Why do situations like this happen?
My experience speaks to two different pain points that data practitioners frequently encounter when dealing with an unfamiliar dataset:
- Firstly, the data didn’t have the prerequisite documentation for future usage appended to it when it was instrumented and the knowledge was lost after a certain period of time.
- Secondly, a lack of clarity on where to look for information meant that the aforementioned documentation was hard to find once it was written.
This unsavory combination is a persistent productivity tax on data teams, as analytics and data science teams spend significant time and energy (potentially up to 60% as per the previously mentioned survey!) on the drudgery necessary for any actual analysis or model training to take place. While this isn’t as easy to measure quantitatively, it’s also a morale tax. I don’t know about you, but I’m never eager to jump straight into building a data model after I’ve spent my whole week just on figuring out what everything means.
I’d also consider this to be the best-case scenario, as both my coworkers and I put in the time and effort to establish (or re-establish) a source of truth. This frequently doesn’t happen due to any number of reasons. For example, a few incorrect assumptions or unverified hearsay can easily lead to overconfidence in one’s understanding of the data, or a seasonal or deadline-driven time crunch simply might not allow for proper due diligence around an unfamiliar dataset. In any case, the end result is frequently misleading or entirely incorrect analysis - leading to potentially disastrous decision-making for the business.
Suffice to say, neither is a desirable outcome for anyone.
Solution: Establish a source of truth by clearly documenting metadata in an easily discoverable place when you instrument new events.
This is where Avo comes in.
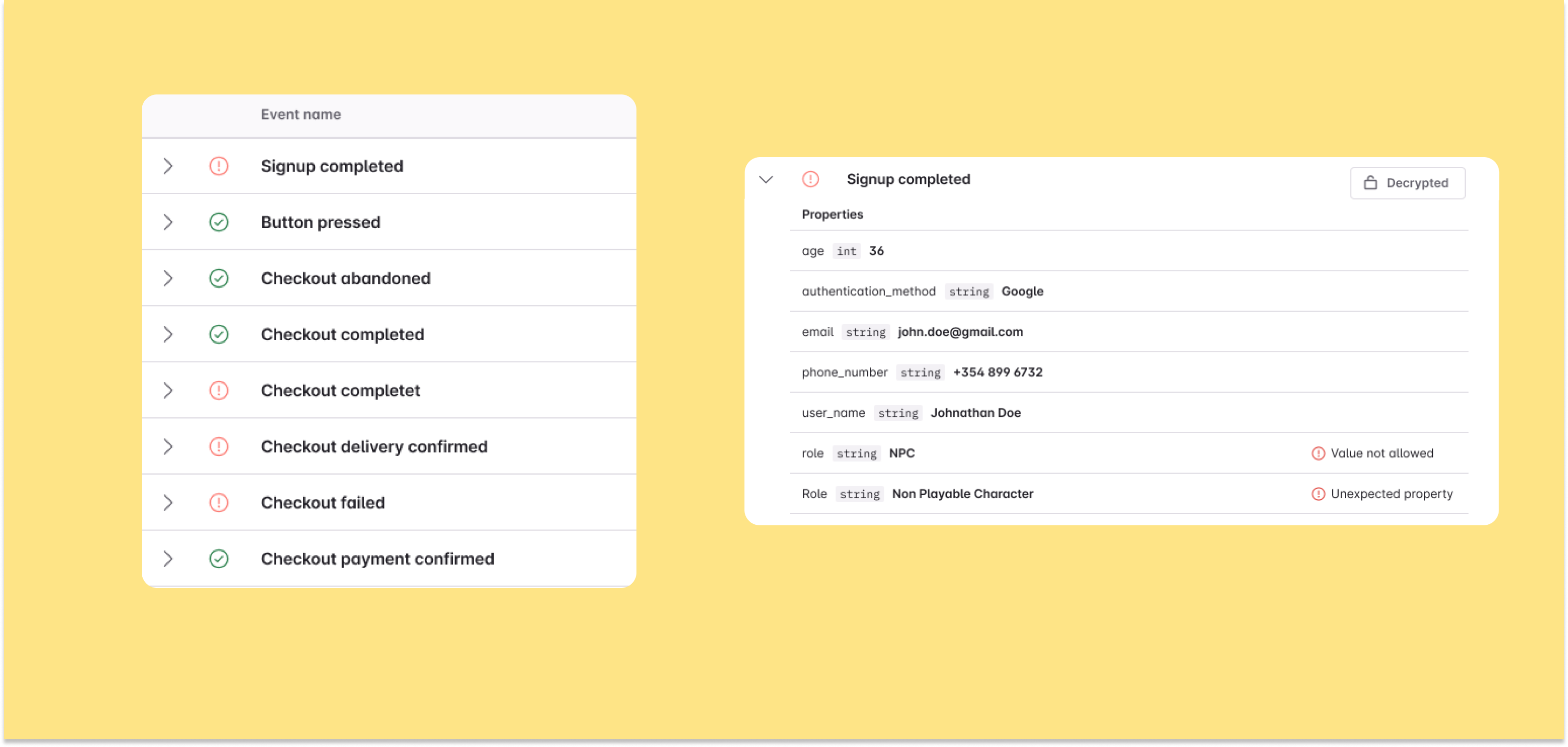
Firstly, it makes it easy for anyone on the team to document any and all relevant information regarding each tracking event. Avo’s Tracking Plan Audit highlights where events and properties are malformed and;or missing any relevant metadata (e.g. general description, where and how the event is triggered, which events include which properties and how frequently, etc.) and makes it easy to append any missing information. For existing data sets that currently lack documentation, the Avo Inspector tool plugs into the data stack and makes it easy to import and append documentation for existing events and properties into the Tracking Plan. Avo’s branched workflow and peer review process ensure that incorrect and/or irrelevant information is caught before it’s added.
Secondly, Avo’s wide range of integrations with CDPs and other data tools means that it can serve as a clear source of truth across the data stack. Once you’ve added any relevant descriptions to your events, they can easily carry through to a variety of destinations such that the same information is available everywhere that you might encounter said events. The end result is that not only does Avo serve both as a primary destination for event and properties information, but it also greatly reduces the need to consult a separate information source while within an analytics or data science workflow.
In combination, Avo provides exactly what I was missing during my not-so-illustrious time with PYMK data: a central repository for data documentation that also plugs in up and downstream for easy discoverability. Not only would it have made documentation easier and more collaborative (whether I were the original documentation writer or not), but it also would have greatly reduced confusion around where to find this documentation for all future users of the dataset.
No single tool can replace the organic company-wide buy-in and effort necessary to build a strong data culture. However, Avo can remove many of the barriers that serve as blockers or excuses along the way by eliminating confusion and bloat throughout the data discovery, instrumentation, and analysis process. If you want to estimate the time and monetary savings that Avo could provide for you and your team, check out our recently launched Avo ROI calculator that can provide both those numbers and auto-generate content to facilitate a conversation with your team and counterparts.
Stay tuned for the next installment, when I’ll talk about how inconsistent casing and formatting can cause big headaches and what Avo does to counter these issues. Until then, happy data designing!
(Image by Gerd Altmann from Pixabay)
Block Quote
