In this article

Opinion
How to successfully do the scary thing and trust anyone in your company to create great event data
The complete checklist that a federated data team can put in place to ensure event data quality that doesn’t create bottlenecks, and thus finally put a data mesh in place for event based data.
You can’t avoid people in your company creating data. This is the case I made in the last post the risk and necessity of domain ownership (and how to mitigate it).
Your role as a data owner in the company boils down to building a system that lets them do what they’ll do anyway, but in a way that scales. In a way that doesn’t leave you stuck in a wild west data mayhem or data bottleneck mayhem.
But while it sounds romantic, it’s also scary to trust people to create data (“a burnt child avoids the fire” is a phrase we have in Icelandic that describes the feeling us data folks have towards this trust). And the typical way data teams mitigate this is to build a system that unintentionally builds bottlenecks. But how do we avoid the data governance paradox? How do we, in practice, provide guardrails to empower domain teams to create high quality event data without building bottlenecks?
Trusting people to create data without creating a wild west or human bottlenecks
The idea of trusting anyone in the company to create data might seem impossible. I know I personally had major trust issues with this. But as Zhamak refers to in the data mesh principles, the role of the federated governance team is not to ensure data quality. Instead, the role of the federated data team is to define how to model what constitutes quality; to ensure there’s a framework for data quality in place that the domain teams can run with on their own—including automatic guardrails so the federated data team trusts that data quality isn’t compromised.
There is a lot of high level advice for data quality flowing out there but we lack tactical steps, or operational translation, to achieve event data quality without creating bottlenecks. The theory is nice, but how do you actually implement this in a growing, overstretched, passionate data team?
Here is my suggestion for a complete checklist that a federated data team can put in place to ensure event data quality that doesn’t create bottlenecks, and thus finally put a data mesh in place for event based data:
The recipe: a system to fulfill data mesh principles for event data quality
1. Framework for event names and level of abstraction
- Systemize how events are named and the level of abstraction to use -> Prevents so many needless, unintentional duplicates (“game started”, “start game”, …) which cause people to use partial data and get the wrong information and prevents taxonomy bloat with separate event names that should be the same event with a property to distinguish between them. There’s a time and place for catch-all events vs user-intent based events.
2. Enforce event naming framework
- Automatically validate whether event specs fulfill event naming framework -> Reduces redundant, repetitive reviews from the people who live and breathe the framework but should spend their time and talent on more meaningful work.
3. Single source of truth
- Keep a source of truth up to date, a dictionary of how things should be done, instead of it living in various different spreadsheets or just Slack or Jira tickets -> Ensures people know what already exists when planning the next release and ensures data consumers have a way to know where they can look for information. This seems impossible, but the following steps makes it a feasible reality.
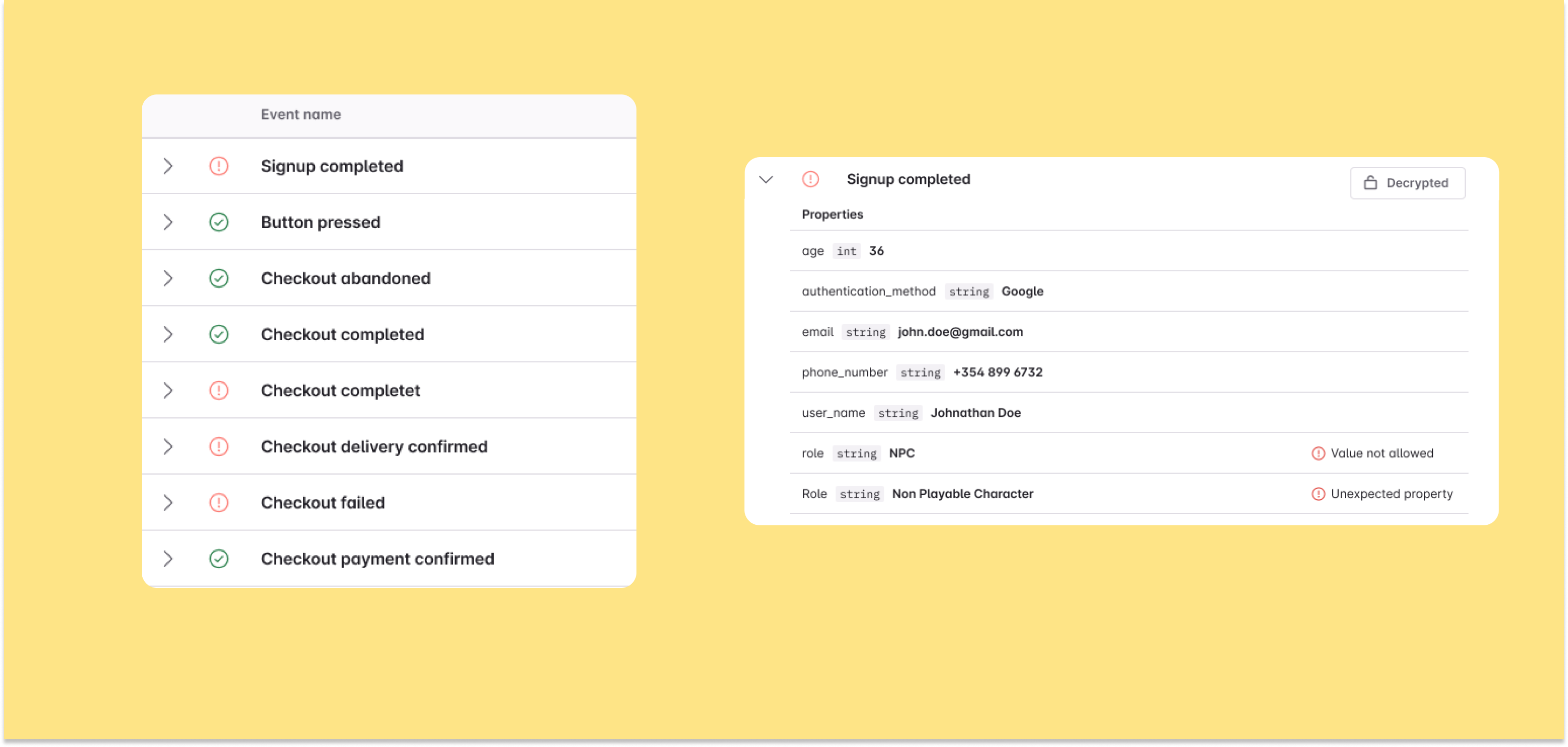
4. Event data observability
- Automatically observe and monitor live data to detect deviations from expected data-> Ensures you always know the expected vs actual, whether something is broken, not live yet, etc., because knowing whether something is reliable or not is necessary for building data trust.
5. Sync across all schema registries
- Choose only one registry for event schema iterations and then automatically sync schemas across all downstream schema registries, from Segment Protocols to your internal JSON schema or documentation in Confluence or Databricks. -> Ensures your schemas are documented correctly everywhere you need them.
6. Source control schemas like code
- Choose a schema documentation solution that allows multiple teams to collaborate in parallel when drafting changes for review -> Prevents bottlenecks and lack of clarity on the origin of schema changes. This is the only way domains can own their own iterations because, just like for your product code base, your schemas require multiple teams iterating at the same time.
7. Design data use-case first (aka metrics-first data design)
- Build a culture where people design and document data from a use-case-first perspective, instead of just showering the next release with events they may seem relevant at some point. I.e. Instead of “which events do I need to track to cover the next release?”, they should think in terms of “What is the goal of the next release and how will I measure its success?” -> Ensures you design better data that covers what you need, ensures you prioritize the right data, and ensures that product engineers understand the purpose and importance of the events they implement in code, which in turn empowers them to make better decisions and take ownership.
8. Document how events relate to metrics (use cases)
- Don’t only document the purpose of the events when asking product engineers for implementation, but also keep a metrics store which documents which events you use for what -> Ensures you have a source of truth not only for your event schemas but for your metric definitions.
9. Document event ownership and stakeholders
- Make it clear who owns the implementation of an event and who will be impacted by changes to it -> Ensures anyone iterating on a schema knows they need buy-in from the owner and stakeholders.
10. Alert when changing something others own or depend on
- Automatically alert event owners and stakeholders when data they own or depend on is subject to change and let the changers know who they’ll be impacting -> Prevents people from making changes that break critical data like the CFO’s dashboard.
How do you put this in place?
The above recipe doesn’t appear out of thin air. It comes from interviewing and working closely with thousands of data practitioners, product engineers, and product managers. People have been building internal solutions for this for decades—including myself and the team behind Avo. This is why we started Avo and are now ensuring event data quality at scale for large enterprise companies. We want you to solve these problems. We’re rooting for you.
If you’re one of the people craving to solve these problems, and you’re considering building something or perhaps already have, I’d love to chat with you and figure out how we can help you to solve these challenges.
… Even if you’re dead set on keeping your internally built solution, please reach out. The world deserves to learn your ways.
In our October Launch Week, we unveiled some powerful new features to empower federated governance with domain ownership.
These included:
- Guardrails to safeguard data design, making it possible for anyone in the company to design great data;
- Stakeholders, a way to divide and conquer your schema management;
- Domain-specific tracking plans and observability solutions;
- Federated governance features that enable data teams to manage data quality at scale;
- And more!
If the challenges highlighted in this and our previous two posts resonate with you, be sure to check out our recent October Launch Week series. You can catch up on a host of new functionality we released in Avo, designed to empower data teams to take ownership of their data quality, at scale.
Special thank you to Glenn Vanderlinden, Timo Dechau, and Thomas in't Veld for their contributions to the ideas in this post.
Block Quote


