In this article

Opinion
Why data governance at scale is so broken (and how we're fixing it)
The case for federated governance with domain ownership. Part 1 of a 3-part series.
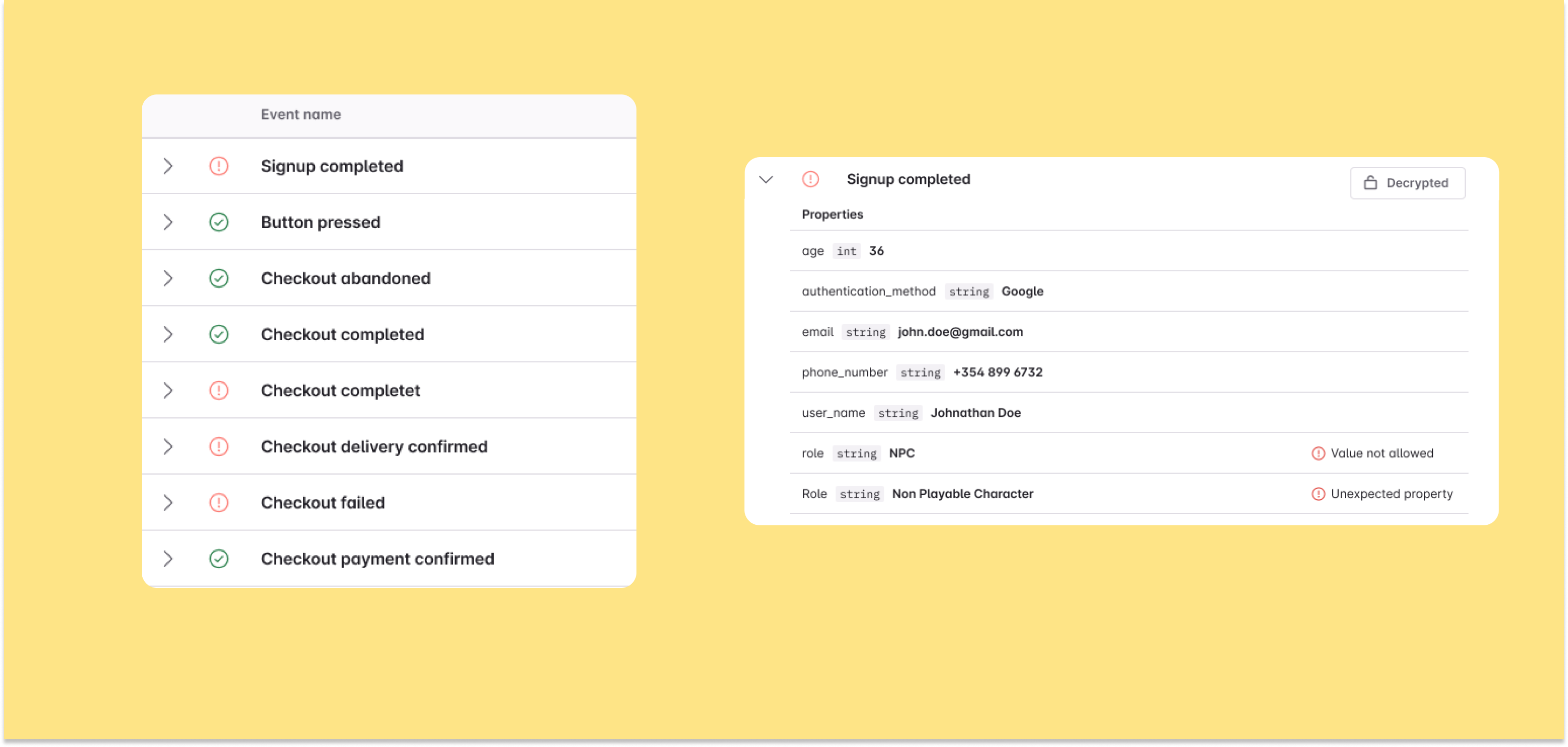
Great data quality happens by design, not by chance. It is the result of thoughtful collaboration between data teams, product managers, and developers.
If you know Avo, you know we’re constantly banging the drum about how analytics is a team sport. When stakeholders work together and have the right tools, the vision of “data as a product” is within reach, and great data quality can be a tangible reality for the whole organization.
The problem is it often feels like data folks, product managers, and developers deploying tracking are off playing different sports. Although we all want the same outcome: data we can rely on to build better user experiences, we’ll never get there unless we’re on the same playing field. That’s exactly what we’re addressing in our next chapter at Avo.
The data governance dilemma
As we explored this problem deeper, we uncovered the cause. It ultimately comes down to ownership—who is responsible for ensuring data quality? Who enforces data design to guarantee consistent data? In our conversations with thousands of data teams trying to elevate their data quality, we kept hearing the same things…
“Data governance is like herding cats”
“The Product Team has gone rogue”
“The Data team is a bottleneck to product updates”
“Shipping fast is making it hard to stay on top of data quality”
Time waits for no one, and it’s true that even mature, experienced teams forego data governance for the sake of speed. If the implementation of high quality data comes at the expense of making product delivery deadlines, many companies will default to lowering the standards of data quality. In a competitive market when your latest product release is the key to survival against competitors, there is no real choice. However, in the long term, poor quality data undermines their ability to leverage data in their product experience and strategy.
We came to coin this conundrum as the “data governance dilemma”, where teams are forced to choose between moving fast with broken data, or enforce data governance processes that slow everything down. And in most cases we end up with the former, where product teams will bypass the governance system because it’s so cumbersome. This reenforces the vicious cycle where data governors to try to govern more, causing more cumbersome systems… which people bypass, and so it continues.
In this scenario, data teams are in a lose-lose situation. But what if there was a path that could satisfy central data leaders as well as domain owners?
There must be a third option. A way to preserve data integrity without grinding everything to a halt, and provide a safe environment for product or domain owners to fend for themselves.
The enablers of data governance at scale (spoiler: data mesh and data contracts)
Data contracts are attractive for several reasons. They align expectations between stakeholders, and allocate responsibility across different parties to drive success.
While the data contract isn’t new, the concept is still being tried and tested by the data community—with some adopting more rigorously than others (and most of us probably not even calling them data contracts even if we’re doing them). Still, it’s a good idea, since it addresses elements at the heart of data governance at scale. Because what is a data contract? A system to document and agree on how you as a team or organization will cooperate to generate useful data:
- Who has ownership of the data?
- How should the data be structured?
- Where, when, and how is the data created?
- Where is the data being sent?
- How is the data being transformed and what business metrics rely on it?
While data contracts differ substantially in how they’re adopted and used from one company to another, they represent an exciting opportunity to bring us closer to the ideal state, where good data is available, quickly.
Could data contracts be an answer to the data governance dilemma, by alleviating the data team bottleneck and “assigning ownership” in a way that makes sense for everyone involved? Yes. Data contracts along with a framework to operate them.
The data mesh principles is another framework that many of us already follow without calling it that. I’m sorry to potentially trigger your allergy to marketing speak, as the entire “data mesh” discussion shenanigans did for me when the internet couldn’t stop hating or loving data mesh a few years back.
What I hated about the data mesh principles framework when it went viral is exactly the same as what I’ve grown love about it; it’s a new way to frame what we’ve all already been trying to work towards for ages.
When I first detected the data mesh trend I thought: “Oh great, someone framing our work in yet another consultant-y framework that’s easy to throw around without getting the nitty gritty of the actual work”—because we all know the devil is in the details. When I finally got over myself I realized it’s frankly a great framing of exactly what I’ve personally been preaching since the early days of event based analytics.
Let’s refresh our memory: What are the data mesh principles? They are four principles that guide us towards building a productive data culture:
- Data as a product
- Self serve analytics
- Federated computational governance
- Domain driven ownership
… I’m not asking for much, just these four simple things. Heh.
Jokes aside, these may seem lofty or even insurmountable, but applying this thinking to event based data governance is absolute key to leveraging it, building products on top of it and making decisions from it. I’ve already talked and written about data as a product and self serve analytics. It’s time to let the other two shine.
Data mesh for event based data: Federated governance with domain-driven ownership
What we’ll be telling you more about is Avo’s technology to empower data practitioners at the central level (as in overseeing the entire organization) and their colleagues at the domain level to operate harmoniously, inspired by the principles of data mesh principles. Internally, we’ve referred to this vision as “federated governance with domain-driven ownership”.
What does this look like?
- Imagine enabling a centralized data governance team to enforce universal data standards and structures, even across multiple products or subsidiary companies.
... But without needing to rely on people to “RTFM” (excuse my vocabulary, but people simply don’t read the manual). The central data team can trust that domain teams will create data that adheres to standards.
- On the other side of the coin, unlock decentralized data management (domain ownership), by providing a safe environment where they can fish for themselves with the help of centrally defined guardrails.
... But without needing to rely on the data team’s slow review process. Domain teams can move quickly and independently while still adhering to preferred data design standards and conventions.
In other words, the company can get good data, fast—the dream that previously couldn’t be imagined with federated governance alone.
We shared some exciting updates on this during our October Launch Week, including new functionality within Avo that makes data mesh principles a reality for our customers relying on event based data. In the meantime, head to the second part of this series where we dive deeper into ways teams and domain owners can create great data at the local level.
Read our next post in the series: The risk of domain ownership (and how to mitigate it).
Block Quote


